SQLITE

- Linux
About

SQLite is an open-source database engine written in the C programming language. It is not a standalone app but a library that software developers embed in their applications. This in-process library implements a self-contained, zero-configuration, serverless, transactional SQL database engine. The SQLite code is in the public domain and is free for any purpose, commercial or private. SQLite is the most broadly deployed database worldwide, including several apps and high-profile projects.
Features
Transactions
Transactions are atomic, isolated, consistent, and durable even after system crashes and power failures.
Zero-configuration
Zero-configuration; no setup or administration required.
Full-featured SQL
Complete SQL implementation with cutting-edge capabilities such as common table expressions, indexes on expressions, partial indexes, JSON, and window functions.
Self-contained
No external dependencies are required, and this makes SQLite the most preferred database engine.
Faster
In some cases, SQLite is quicker than direct filesystem I/O.
SQL language extensions
SQLite renders numerous enhancements to the SQL language not usually found in other database engines.
- Type virtual machines in the search.
- Under Services, select Virtual machines.
- In the Virtual machines page, select Add. The Create a virtual machine page opens.
- In the Basics tab, under Project details, make sure the correct subscription is selected and then choose to Create new resource group. Type myResourceGroup for the name.*.
- Under Instance details, type myVM for the Virtual machine name, choose East US for your Region, and choose Ubuntu 18.04 LTS for your Image. Leave the other defaults.
- Under Administrator account, select SSH public key, type your user name, then paste in your public key. Remove any leading or trailing white space in your public key.
- Under Inbound port rules > Public inbound ports, choose Allow selected ports and then select SSH (22) and HTTP (80) from the drop-down.
- Leave the remaining defaults and then select the Review + create button at the bottom of the page.
- On the Create a virtual machine page, you can see the details about the VM you are about to create. When you are ready, select Create.
It will take a few minutes for your VM to be deployed. When the deployment is finished, move on to the next section.
Connect to virtual machine
Create an SSH connection with the VM.
- Select the Connect button on the overview page for your VM.
- In the Connect to virtual machine page, keep the default options to connect by IP address over port 22. In Login using VM local account a connection command is shown. Select the button to copy the command. The following example shows what the SSH connection command looks like:
bashCopy
ssh azureuser@10.111.12.123
- Using the same bash shell you used to create your SSH key pair (you can reopen the Cloud Shell by selecting >_ again or going to https://shell.azure.com/bash), paste the SSH connection command into the shell to create an SSH session.
Usage/Deployment Instructions
Step 1: Access the Sqlite in Azure Marketplace and click on Get it now button.
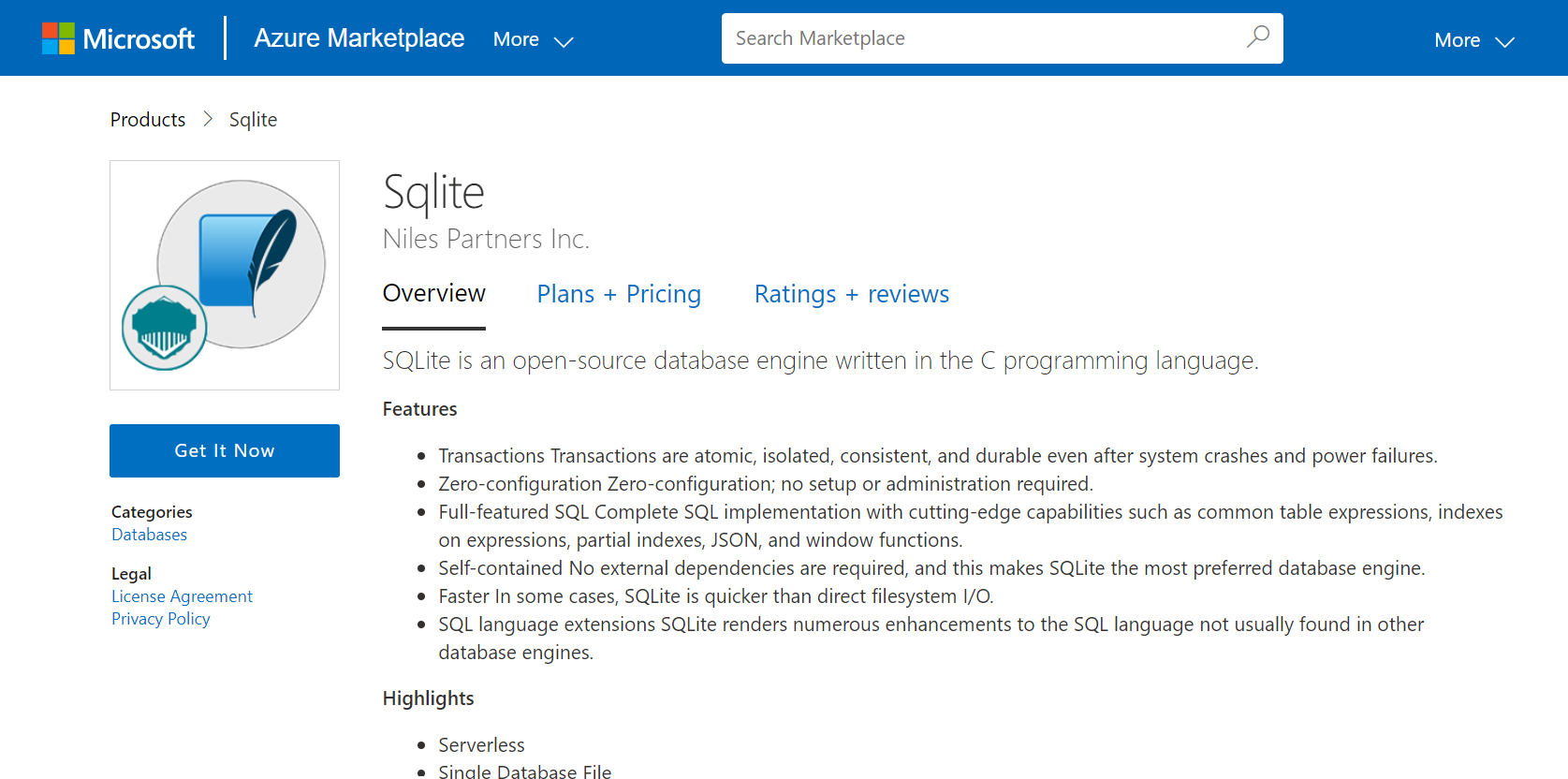

Click on Continue and then click on Create.
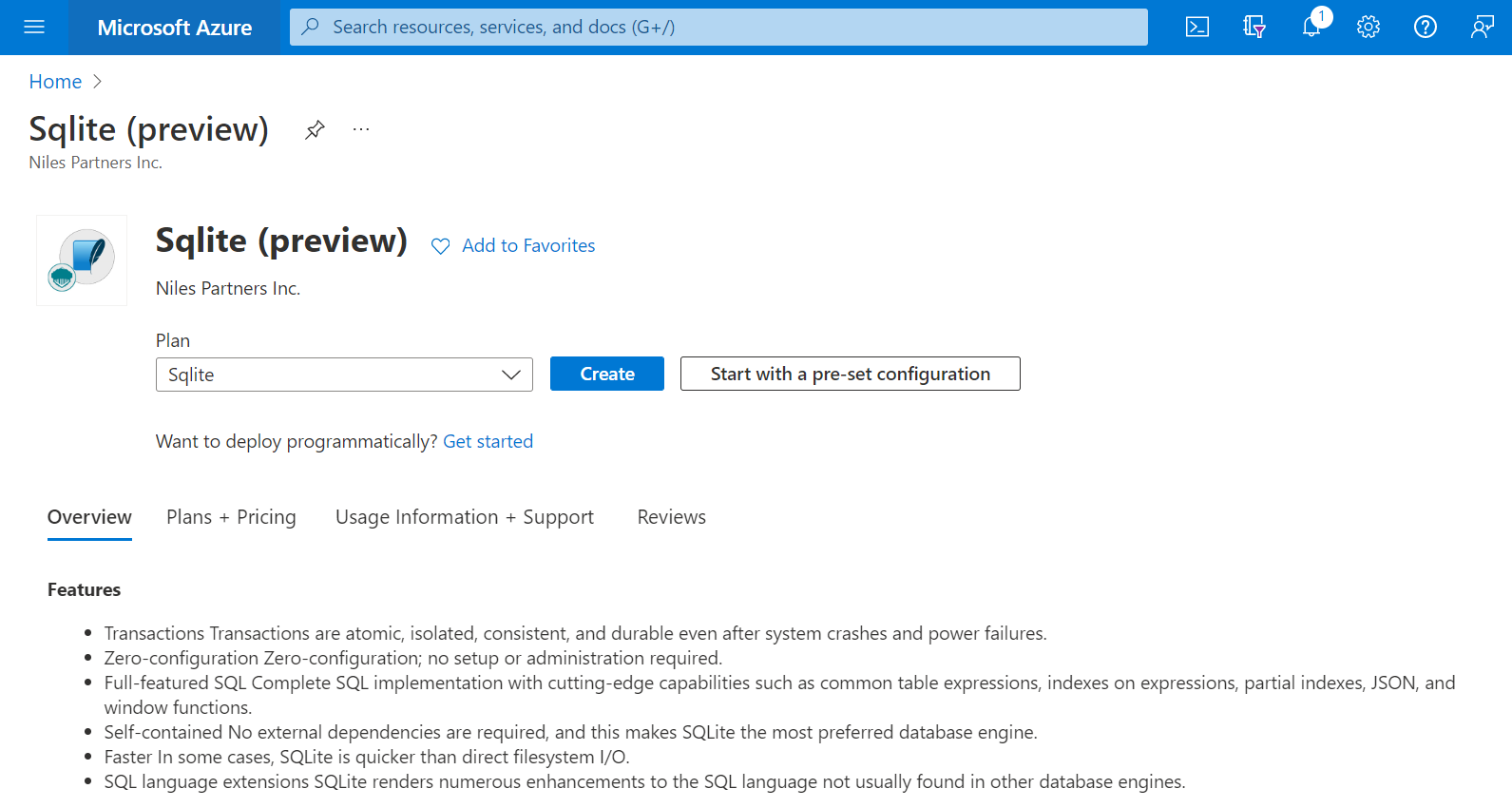
Step 2: Now to create a virtual machine, enter or select appropriate values for zone, machine type, resource group and so on as per your choice.
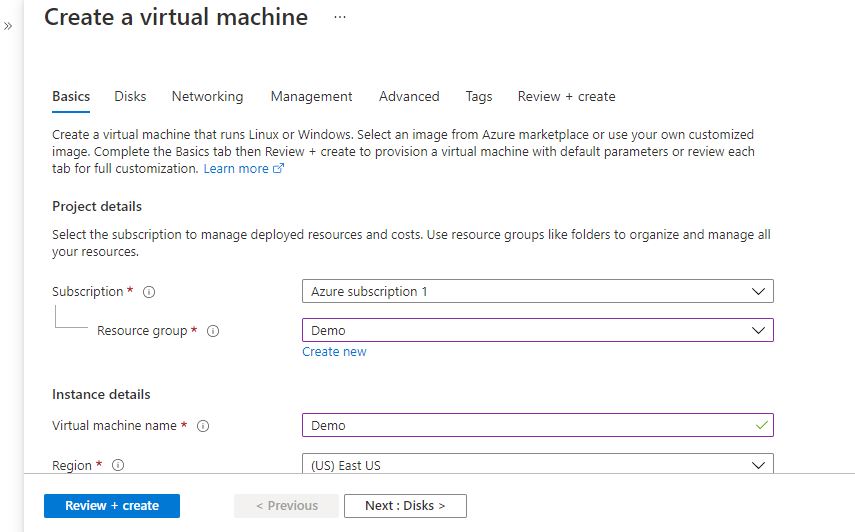
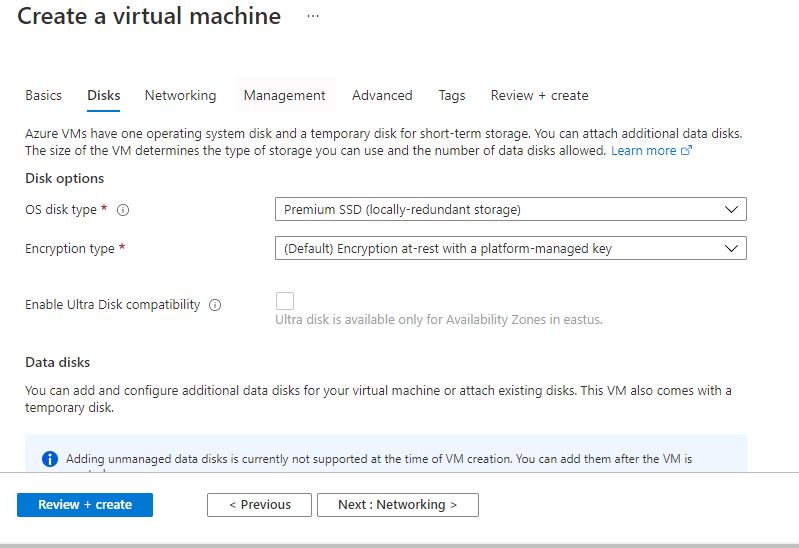
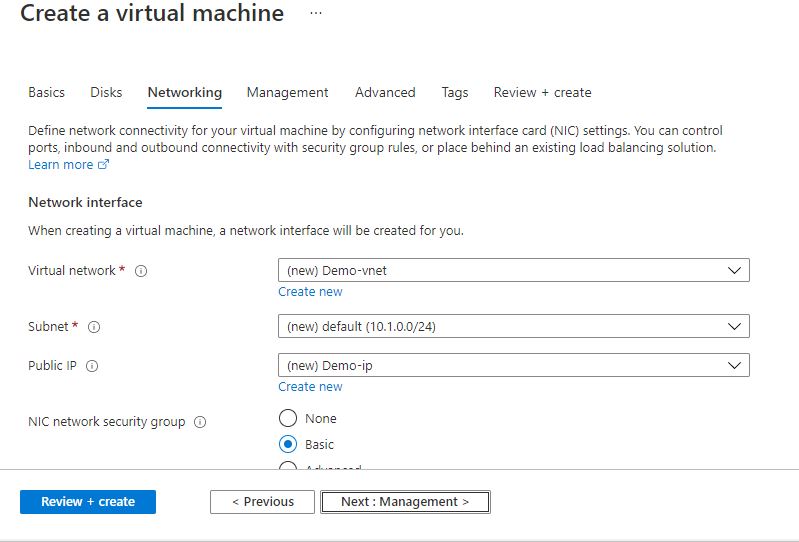
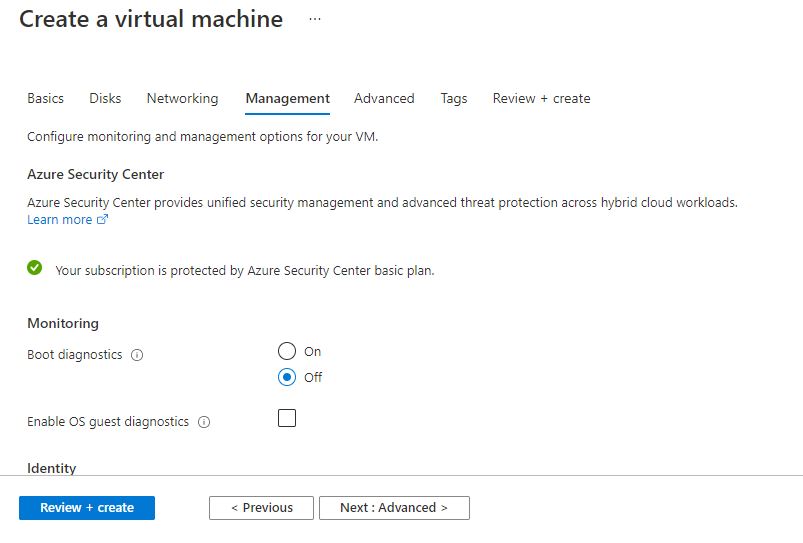
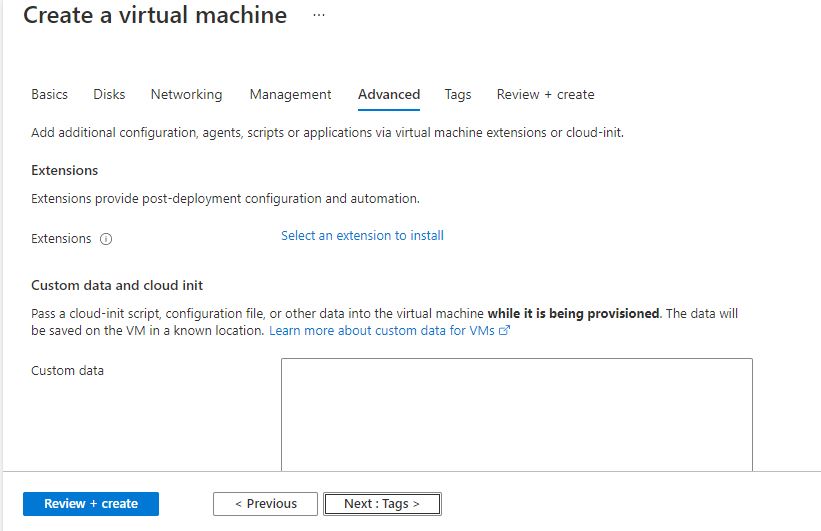
Click on Review + create.
Step 3: The below window confirms that VM was deployed.
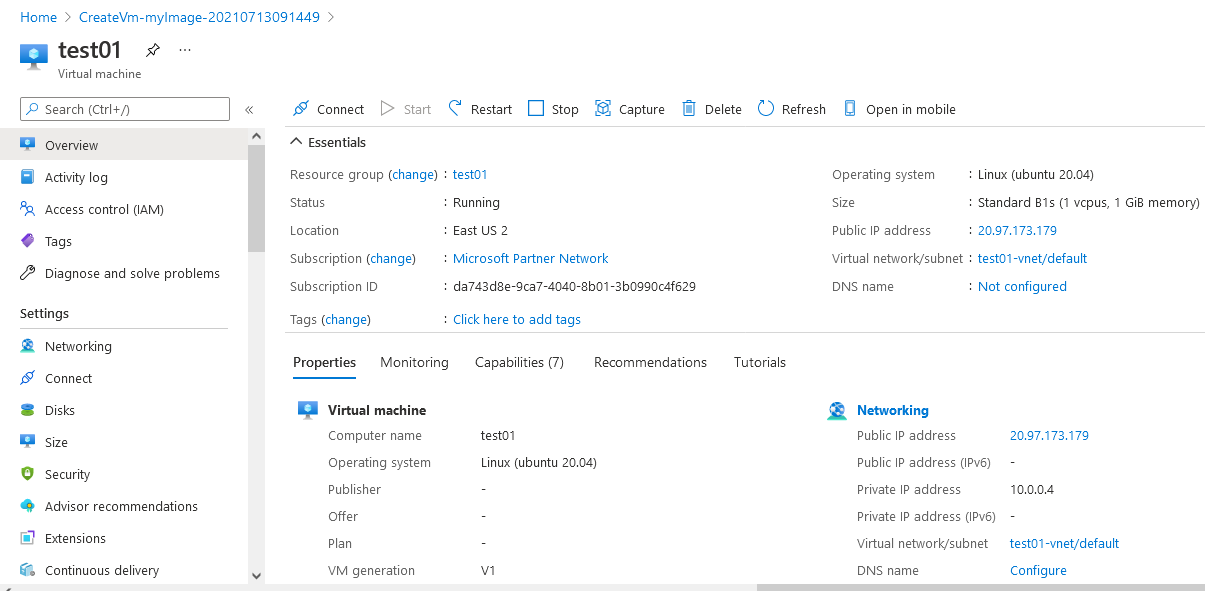
Step 4: Open putty and connect with your machine. Add IP address of the running virtual machine.
Step 5: Login with user name and password that you provided during machine creation.
Step 6: Check if the service is up
$ systemctl status sqlite3
If down than run command
$ systemctl start sqlite3
To verify the installation, check the software’s version:
$ sqlite3 –version
Step 7: Creating a SQLite Database
$ sqlite3 test
Following this, your prompt will change. A new prefix, sqlite>, now appears:
Step 8: Creating a SQLite Table
$ CREATE TABLE test(id integer NOT NULL, name text NOT NULL, testtype text NOT NULL, length integer NOT NULL);
Step 9: Inserting Values into Tables
$ INSERT INTO tablename VALUES(values go here);
Step 10: Reading Tables in SQLite
$ SELECT * FROM test;
Step 11: Updating Tables in SQLite
Adding Columns to SQLite Tables
Use ALTER TABLE to create a new column. This new column will track each test age in years:
$ ALTER TABLE sharks ADD COLUMN age integer;
You now have a fifth column, age.
Updating Values in SQLite Tables
Using the UPDATE command, add new age values for each of your test:
$ UPDATE test SET age = 272 WHERE id=1;
Step 12: Deleting Information in SQLite
$ DELETE FROM sharks WHERE age <= 200;
Enjoy your Application.
- (510) 298-5936
Submit Your Request
Until now, small developers did not have the capital to acquire massive compute resources and ensure they had the capacity they needed to handle unexpected spikes in load. Amazon EC2 enables any developer to leverage Amazon’s own benefits of massive scale with no up-front investment or performance compromises. Developers are now free to innovate knowing that no matter how successful their businesses become, it will be inexpensive and simple to ensure they have the compute capacity they need to meet their business requirements.
The “Elastic” nature of the service allows developers to instantly scale to meet spikes in traffic or demand. When computing requirements unexpectedly change (up or down), Amazon EC2 can instantly respond, meaning that developers have the ability to control how many resources are in use at any given point in time. In contrast, traditional hosting services generally provide a fixed number of resources for a fixed amount of time, meaning that users have a limited ability to easily respond when their usage is rapidly changing, unpredictable, or is known to experience large peaks at various intervals.
Traditional hosting services generally provide a pre-configured resource for a fixed amount of time and at a predetermined cost. Amazon EC2 differs fundamentally in the flexibility, control and significant cost savings it offers developers, allowing them to treat Amazon EC2 as their own personal data center with the benefit of Amazon.com’s robust infrastructure.
When computing requirements unexpectedly change (up or down), Amazon EC2 can instantly respond, meaning that developers have the ability to control how many resources are in use at any given point in time. In contrast, traditional hosting services generally provide a fixed number of resources for a fixed amount of time, meaning that users have a limited ability to easily respond when their usage is rapidly changing, unpredictable, or is known to experience large peaks at various intervals.
Secondly, many hosting services don’t provide full control over the compute resources being provided. Using Amazon EC2, developers can choose not only to initiate or shut down instances at any time, they can completely customize the configuration of their instances to suit their needs – and change it at any time. Most hosting services cater more towards groups of users with similar system requirements, and so offer limited ability to change these.
Finally, with Amazon EC2 developers enjoy the benefit of paying only for their actual resource consumption – and at very low rates. Most hosting services require users to pay a fixed, up-front fee irrespective of their actual computing power used, and so users risk overbuying resources to compensate for the inability to quickly scale up resources within a short time frame.
No. You do not need an Elastic IP address for all your instances. By default, every instance comes with a private IP address and an internet routable public IP address. The private address is associated exclusively with the instance and is only returned to Amazon EC2 when the instance is stopped or terminated. The public address is associated exclusively with the instance until it is stopped, terminated or replaced with an Elastic IP address. These IP addresses should be adequate for many applications where you do not need a long lived internet routable end point. Compute clusters, web crawling, and backend services are all examples of applications that typically do not require Elastic IP addresses.
You have complete control over the visibility of your systems. The Amazon EC2 security systems allow you to place your running instances into arbitrary groups of your choice. Using the web services interface, you can then specify which groups may communicate with which other groups, and also which IP subnets on the Internet may talk to which groups. This allows you to control access to your instances in our highly dynamic environment. Of course, you should also secure your instance as you would any other server.
Highlights
- Serverless
- Single Database File
- Stable Cross-Platform Database File
- Compact
- Manifest typing
- Variable-length records
- Readable source code
Application Installed
